


Benchmarks
 Three papers best describe the miniboxing transformation and benchmarks:
Three papers best describe the miniboxing transformation and benchmarks:
- Miniboxing (OOPSLA 2013) - the first miniboxing paper, describing the representation,
- Late Data Layout (OOPSLA 2014) - the foundation of miniboxing (also described in detail here) and
- Miniboxing the Linked List (tech report) - describes the miniboxing transformation for Scala collections.
This document will only present a few of the bechmarks:
- macrobenchmarks - large and complex programs
- microbenchmarks - small and focused benchmarks
- bytecode size comparisons
Macrobenchmarks
Scala Collections
To evaluate the miniboxing plugin, we implemented a mock-up of the Scala collections linked list and benchmarked the performance. The result: 1.5x-4x speedup just by adding the @miniboxed annotation. And it’s worth pointing out our mock-up included all the common patterns found in the library: Builder, Numeric, Traversable, Seq, closures, tuples etc.
The benchmark we ran is fitting a linear curve to a given set of points using the Least Squares method. Basically, we made a custom library and benchmarked this code:
val xs: List[Double] = // list of x coordinates
val ys: List[Double] = // list of y coordinates
// list of (x,y) coordinates:
val xys = xs.zip(ys)
// intermediary sums:
val sumx = xs.sum
val sumy = ys.sum
val sumxy = xys.map(mult).sum
val sumsquare = xs.map(square).sum
// slope and intercept approximation:
val slope = (size * sumxy - sumx * sumy) / (size * sumsquare - sumx * sumx)
val intercept = (sumy * sumsquare - sumx * sumxy) / (size * sumsquare - sumx * sumx)With infinite heap memory (no garbage collection overhead)
We ran this code with two versions of the linked list: one with the plugin activated and one with generic classes. The numbers were obtained on an i7 server machine with 32GB of RAM, and we made sure no garbage collections occured (-Xmx16g, -Xms16g):
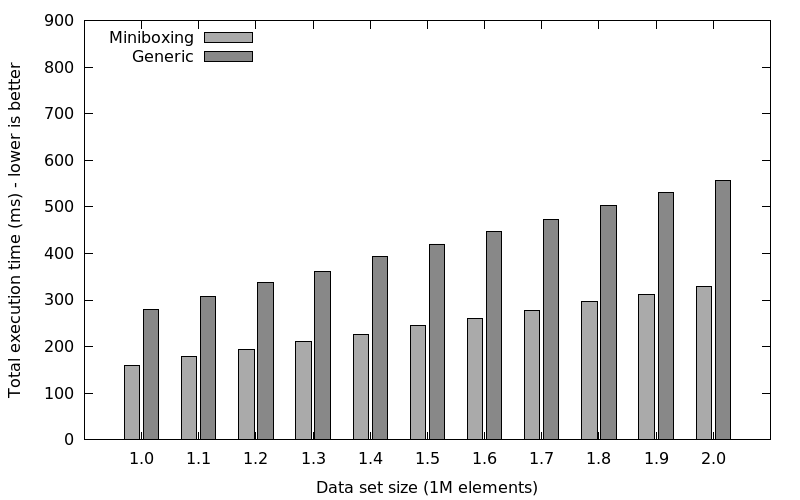
This shows miniboxed linked lists are 1.5x to 2x faster than generic collections, despite the fact that linked lists are not contiguous, thus reducing the benefits of miniboxing. We have also tested specialization, but it ran out of memory and we were unable to get any garbage collection-free runs above 1500000 elements (we suspect this is due to bug SI-3585 Specialized class should not have duplicate fields, but haven’t examined in depth).
With limited heap memory
We also wanted to test how miniboxing copes with garbage collection cycles compared to the generic library. To do so, we limited the heap size to 2G (-Xmx2g, -Xms2g, -XX:+UseParallelGC):
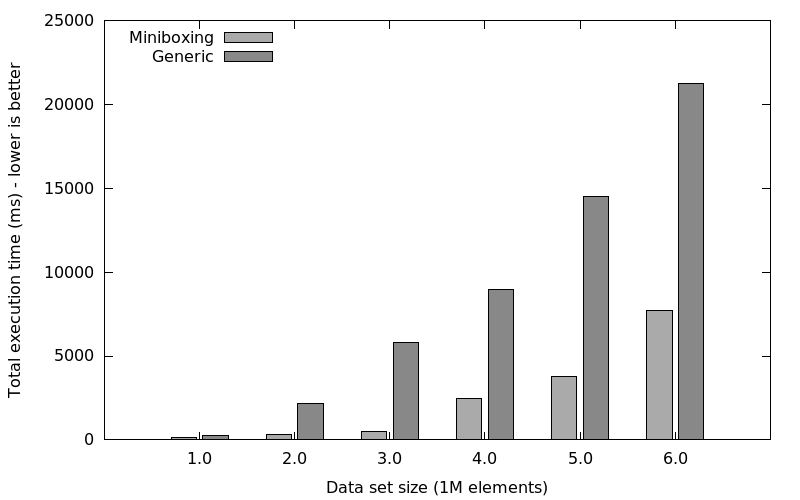
To summarize, on linked lists, we can expect speedups between 1.5x and 4x, despite the non-contiguous nature of the linked list.
The full description of this experiment is available here.
Spire
A separate article describes the performance of the spire numeric abstraction library when using miniboxing.
Microbenchmarks
Another important benchmark is the ArrayBuffer.reverse. This is the most difficult benchmark to get right, since the
miniboxing transformation interacts with the Java Virtual Machine optimization heuristics and, if the transformation is
not done correctly, miniboxing can actually hurt performance (more details in the OOPSLA paper).
These are our current results:
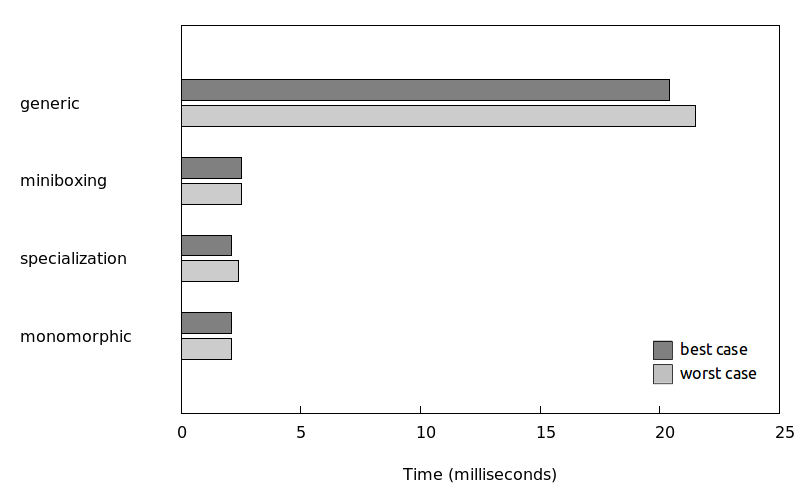
Where:
genericis the generic codeminiboxingis the code generated by our pluginspecializationis the code generated by the@specializedannotation in Scalamonomorphicis the code specialized by hand
After removing generic:
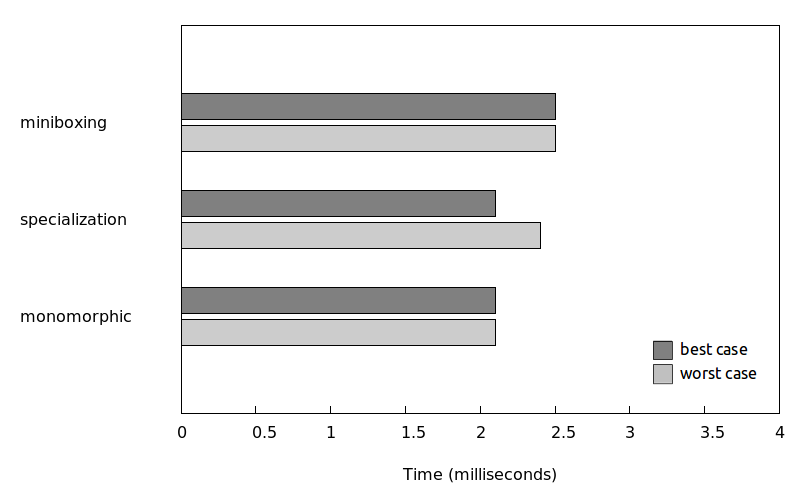
These benchmarks are further described in a Miniboxing OOPSLA’13 paper.
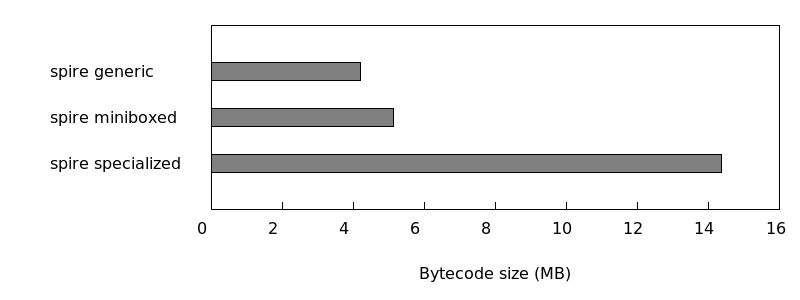
Bytecode Size
When comparing the total bytecode size for spire we see a 4.5x bytecode reduction:
More Benchmarks
The OOPSLA’13 paper presents several other benchmarks:
- performance microbenchmarks
- on the HotSpot JVM with the Server compiler
- on the HotSpot JVM with the Graal compiler
- interpreter performance microbenchmarks
- bytecode size
- classloader overhead
- performance impact
- heap consumption
The SCALA’14 paper presents:
- a high-level overview of patterns in Scala
- benchmarks for a mock-up of the Scala collection linked list
Conclusion
In short, miniboxed code:
- is up to 22x faster than generic code
- it surpasses the performance of specialization
- is marginally slower compared to monomorphic code, with an overhead of about 10%
Comments
Comments are always welcome! But to make the best use of them, please consider this:
- If you have questions or feedback regarding the content of this page, please leave us a comment!
- If you have general questions about the miniboxing plugin, please ask on the mailing List.
- If you found a bug, please let us know on the github issue tracker.
Thanks! Looking forward to your messages!
comments powered by Disqus